

Redis란?
키-밸류(Key-Value) 데이터 구조에 기반해 데이터들을 저장하고 관리하기 위한 오픈소스 기반의 비관계형 데이터베이스 관리 시스템이다. 다양한 메모리 구조 집합을 제공하여 데이터 저장 뿐만 아니라 다양한 목적으로 사용할 수 있다.
장점은 빠른 처리 속도, 단점은 저장 공간의 제약
레디스는 메모리에 데이터를 저장하기 때문에 빠른 처리 속도가 장점이지만 저장 공간에 제약이 있다. 이 단점 때문에 주로 보조 데이터 저장소로 사용한다. 레디스 클러스트 기능을 사용하여 저장 공간을 확장할 수 있다. 또한 저장된 데이터를 영구적으로 디스크에 저장할 수 있는 백업 기능도 제공한다.
Redis 데이터 백업 방식
메모리에 데이터를 관리하므로 매우 빠른 속도로 데이터를 저장 및 조회할 수 있다. 하지만 메모리 특성상 저장된 데이터는 사라질 가능성이 있다. 이를 보완하고자 레디스는 관리하고 있는 데이터에 영속성을 제공한다. 즉 메모리에 있는 데이터를 디스크에 백업하는 기능을 제공하며, RDB 방식이나, AOF 방식으로 백업할 수 있다.
1) RDB(Redis Database) : 메모리에 있는 데이터 전체에서 스냅샷을 작성하고, 이를 디스크로 저장하는 방식
- 특정 시간마다 여러 개의 스냅샷을 생성하고, 데이터를 복원해야 한다면 스냅샷 파일을 그대로 로딩만 하면 됨.
- 하지만, 스냅샷 이후 변경된 데이터는 복구할 수 없음 -> 데이터 유실(loss)
2) AOF(Append Only File) : 데이터가 변경되는 이벤트가 발생하면 이를 모두 로그에 저장하는 방식.
- 데이터를 생성, 수정, 삭제하는 이벤트를 초 단위로 취합 및 로그 파일에 작성
- 모든 데이터의 변경 기록들을 보관하고 있으므로 최신 데이터 정보를 백업 가능
- RDB 방식에 비해 데이터 유실량이 적음(초 단위 데이터는 유실 가능)
- RDB 방식보다 로딩 속도가 느리고 파일 크기가 큰 것이 단점
=> 일부 데이터 손실에 영향이 받지 않는 경우(캐시로만 사용할 때), RDB
=> 장애 상황 직전까지의 모든 데이터가 보장되어야 할 경우, AOF
=> 강력한 내구성이 필요한 경우, RDB + AOF
=> 레디스는 일반적으로 AOF와 RDB를 동시에 사용하여 데이터를 백업한다.
Redis 사용 용도
1. 주 데이터 저장소 : AOF, RDB 백업 기능과 레디스 아키텍처를 사용하여 주 저장소로 데이터를 저장할 수 있다. 하지만 메모리 특성상 용량이 큰 데이터 저장소로는 적절하지 않다.
2. 데이터 캐시 : 인메모리 데이터 저장소이므로 주 저장소의 데이터를 캐시하여 빠르게 데이터를 읽을 수 있다. 캐시된 데이터는 한 곳에 저장되는 중앙 집중형 구조로 구성한다 -> 데이터 일관성 유지 가능
3. 분산 락(Distributed lock) : 분산 환경에서 여러 시스템이 동시에 데이터를 처리할 때는 특정 공유 자원의 사용 여부를 검증하여 데드락을 방지할 필요가 있다. 이때 레디스를 분산 락으로 사용할 수 있다.
4. 순위 계산 : 레디스에서 제공하는 ZSet(Sorted Set) 자료 구조를 이용하여 순위 계산 용도로 사용하기도 한다. ZSet은 정렬 기능이 포함된 Set 자료 구조 이므로 쉽고 빠르게 순위를 계산할 수 있다.
Redis 자료 구조
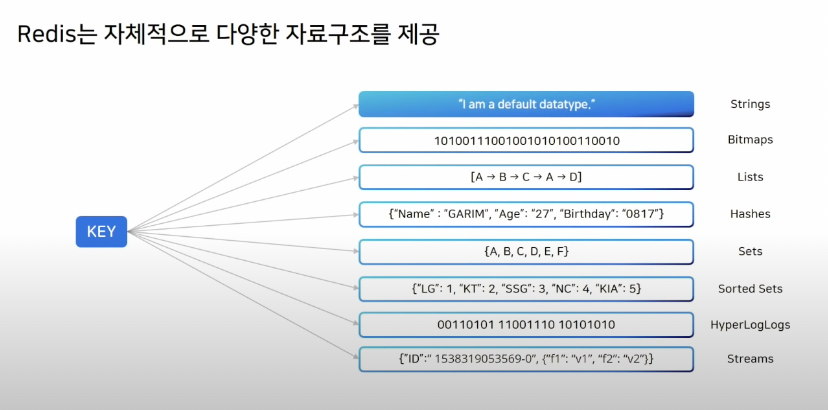
레디스는 다양한 형태의 자료 구조를 제공한다. 기본적으로 키-밸류(Key-Value) 형태의 구조를 띄며, 밸류가 사용하는 자료 구조에 따라 여러 기능을 사용할 수 있다. 즉, 어떤 형태의 자료구조를 사용하더라도 키는 반드시 필요하다.
- String : 문자열 데이터를 저장 및 조회할 수 있는 기본 자료 구조
- Bitmap : 비트 연산을 사용할 수 있는 자료 구조
- List : 리스트 데이터, 그림과 같이 리스트 아이템은 링크드 리스트(Linked List) 형태로 서로 연결되어 있다.
- Hashe : 해시 자료 구조, 해시 필드(Field)와 밸류(Value)로 구성된다. 해시 데이터는 레디스 키와 매핑되어 있으므로 해시 밸류를 생성 및 조회하려면 레디스 키와 필드를 동시에 사용해야 한다.
- Set : 리스트와 비슷한 집합 데이터, 중복을 허용하지 않는 자료구조.
- Sorted Set(ZSet) : Set과 비슷한 집합 데이터, 정렬 기능을 제공한다. 중복을 허용하지 않으며, 이 때 데이터는 스코어와 함께 저장할 수 있다. Sorted Set은 스코어 값을 사용하여 정렬하고, 스코어 값이 중복되면 사전순으로 정렬한다.
- Hypperloglog : 집합의 데이터 개수를 추정할 수 있는 알고리즘 이름이자 이를 사용할 수 있는 레디스 자료구조이다.
- Stream : 레디스 5.0 버전부터 제공하는 기능, 이벤트성 로그를 처리할 수 있다. 일종의 메세지 서비스 기능. 스트림 키 이름과 값, 필드를 사용할 수 있는 자료 구조 형태를 띈다.
'백엔드 > DBMS' 카테고리의 다른 글
| [DATAGRIP] 트랜잭션 commit 수동/자동 설정 (0) | 2024.06.20 |
|---|---|
| [SQL] 프로시저와 함수의 차이 (0) | 2024.01.16 |
Redis란?
키-밸류(Key-Value) 데이터 구조에 기반해 데이터들을 저장하고 관리하기 위한 오픈소스 기반의 비관계형 데이터베이스 관리 시스템이다. 다양한 메모리 구조 집합을 제공하여 데이터 저장 뿐만 아니라 다양한 목적으로 사용할 수 있다.
장점은 빠른 처리 속도, 단점은 저장 공간의 제약
레디스는 메모리에 데이터를 저장하기 때문에 빠른 처리 속도가 장점이지만 저장 공간에 제약이 있다. 이 단점 때문에 주로 보조 데이터 저장소로 사용한다. 레디스 클러스트 기능을 사용하여 저장 공간을 확장할 수 있다. 또한 저장된 데이터를 영구적으로 디스크에 저장할 수 있는 백업 기능도 제공한다.
Redis 데이터 백업 방식
메모리에 데이터를 관리하므로 매우 빠른 속도로 데이터를 저장 및 조회할 수 있다. 하지만 메모리 특성상 저장된 데이터는 사라질 가능성이 있다. 이를 보완하고자 레디스는 관리하고 있는 데이터에 영속성을 제공한다. 즉 메모리에 있는 데이터를 디스크에 백업하는 기능을 제공하며, RDB 방식이나, AOF 방식으로 백업할 수 있다.
1) RDB(Redis Database) : 메모리에 있는 데이터 전체에서 스냅샷을 작성하고, 이를 디스크로 저장하는 방식
- 특정 시간마다 여러 개의 스냅샷을 생성하고, 데이터를 복원해야 한다면 스냅샷 파일을 그대로 로딩만 하면 됨.
- 하지만, 스냅샷 이후 변경된 데이터는 복구할 수 없음 -> 데이터 유실(loss)
2) AOF(Append Only File) : 데이터가 변경되는 이벤트가 발생하면 이를 모두 로그에 저장하는 방식.
- 데이터를 생성, 수정, 삭제하는 이벤트를 초 단위로 취합 및 로그 파일에 작성
- 모든 데이터의 변경 기록들을 보관하고 있으므로 최신 데이터 정보를 백업 가능
- RDB 방식에 비해 데이터 유실량이 적음(초 단위 데이터는 유실 가능)
- RDB 방식보다 로딩 속도가 느리고 파일 크기가 큰 것이 단점
=> 일부 데이터 손실에 영향이 받지 않는 경우(캐시로만 사용할 때), RDB
=> 장애 상황 직전까지의 모든 데이터가 보장되어야 할 경우, AOF
=> 강력한 내구성이 필요한 경우, RDB + AOF
=> 레디스는 일반적으로 AOF와 RDB를 동시에 사용하여 데이터를 백업한다.
Redis 사용 용도
1. 주 데이터 저장소 : AOF, RDB 백업 기능과 레디스 아키텍처를 사용하여 주 저장소로 데이터를 저장할 수 있다. 하지만 메모리 특성상 용량이 큰 데이터 저장소로는 적절하지 않다.
2. 데이터 캐시 : 인메모리 데이터 저장소이므로 주 저장소의 데이터를 캐시하여 빠르게 데이터를 읽을 수 있다. 캐시된 데이터는 한 곳에 저장되는 중앙 집중형 구조로 구성한다 -> 데이터 일관성 유지 가능
3. 분산 락(Distributed lock) : 분산 환경에서 여러 시스템이 동시에 데이터를 처리할 때는 특정 공유 자원의 사용 여부를 검증하여 데드락을 방지할 필요가 있다. 이때 레디스를 분산 락으로 사용할 수 있다.
4. 순위 계산 : 레디스에서 제공하는 ZSet(Sorted Set) 자료 구조를 이용하여 순위 계산 용도로 사용하기도 한다. ZSet은 정렬 기능이 포함된 Set 자료 구조 이므로 쉽고 빠르게 순위를 계산할 수 있다.
Redis 자료 구조
레디스는 다양한 형태의 자료 구조를 제공한다. 기본적으로 키-밸류(Key-Value) 형태의 구조를 띄며, 밸류가 사용하는 자료 구조에 따라 여러 기능을 사용할 수 있다. 즉, 어떤 형태의 자료구조를 사용하더라도 키는 반드시 필요하다.
- String : 문자열 데이터를 저장 및 조회할 수 있는 기본 자료 구조
- Bitmap : 비트 연산을 사용할 수 있는 자료 구조
- List : 리스트 데이터, 그림과 같이 리스트 아이템은 링크드 리스트(Linked List) 형태로 서로 연결되어 있다.
- Hashe : 해시 자료 구조, 해시 필드(Field)와 밸류(Value)로 구성된다. 해시 데이터는 레디스 키와 매핑되어 있으므로 해시 밸류를 생성 및 조회하려면 레디스 키와 필드를 동시에 사용해야 한다.
- Set : 리스트와 비슷한 집합 데이터, 중복을 허용하지 않는 자료구조.
- Sorted Set(ZSet) : Set과 비슷한 집합 데이터, 정렬 기능을 제공한다. 중복을 허용하지 않으며, 이 때 데이터는 스코어와 함께 저장할 수 있다. Sorted Set은 스코어 값을 사용하여 정렬하고, 스코어 값이 중복되면 사전순으로 정렬한다.
- Hypperloglog : 집합의 데이터 개수를 추정할 수 있는 알고리즘 이름이자 이를 사용할 수 있는 레디스 자료구조이다.
- Stream : 레디스 5.0 버전부터 제공하는 기능, 이벤트성 로그를 처리할 수 있다. 일종의 메세지 서비스 기능. 스트림 키 이름과 값, 필드를 사용할 수 있는 자료 구조 형태를 띈다.
'백엔드 > DBMS' 카테고리의 다른 글
| [DATAGRIP] 트랜잭션 commit 수동/자동 설정 (0) | 2024.06.20 |
|---|---|
| [SQL] 프로시저와 함수의 차이 (0) | 2024.01.16 |